Robots.txt là một trong những file đơn giản nhất trên website, nhưng đồng thời, nó cũng lại là một trong những thứ dễ gây rối nhất. Chỉ cần một ký tự bị thiếu là có thể phá đi thành quả SEO của bạn rồi. Hơn nữa, nó còn ngăn cả các công cụ tìm kiếm truy cập nội dung quan trọng trên site đó.
Đây là lý do tại sao mà việc các cấu hình trong robots.txt bị sai lại cực kỳ phổ biến – ngay cả những người có kinh nghiệm làm SEO cũng vẫn còn mắc phải.
Trong bài viết hướng dẫn này, bạn sẽ được biết về:

Robots.txt là gì?
Robots.txt là một tệp văn bản đơn giản được đặt trên máy chủ website để hướng dẫn các công cụ tìm kiếm (robots, bots, hoặc crawlers) về cách quét và lập chỉ mục nội dung trên trang web đó. Tệp này nằm ở thư mục gốc của website và là một phần quan trọng trong việc tối ưu hóa công cụ tìm kiếm (SEO).
Mục đích chính của robots.txt:
-
Hướng dẫn bot về các phần của trang web: Bạn có thể sử dụng robots.txt để chỉ định các phần của trang web mà bạn không muốn bot truy cập hoặc lập chỉ mục, chẳng hạn như trang quản trị, trang chứa dữ liệu nhạy cảm, hoặc các trang không cần thiết hiển thị trên kết quả tìm kiếm.
-
Tối ưu hóa việc lập chỉ mục: Thông qua robots.txt, bạn có thể giúp các công cụ tìm kiếm tập trung vào những nội dung quan trọng nhất và bỏ qua những trang không liên quan. Điều này giúp tiết kiệm tài nguyên khi bot quét website của bạn và cải thiện thứ hạng trang web trên kết quả tìm kiếm.
Cách hoạt động của robots.txt:
Khi một bot truy cập vào một website, nó sẽ kiểm tra tệp robots.txt để xem có bất kỳ quy tắc nào mà nó cần tuân theo không. Nếu có, bot sẽ thực hiện theo những hướng dẫn này, chẳng hạn như không truy cập vào một số trang hoặc thư mục nhất định. Tuy nhiên, tệp robots.txt chỉ là một gợi ý, và một số bot có thể không tuân thủ.
Cấu trúc cơ bản của tệp robots.txt:
- User-agent: Định nghĩa loại bot mà bạn muốn áp dụng quy tắc. Ký hiệu
*nghĩa là quy tắc này áp dụng cho tất cả các bot. - Disallow: Chỉ định các trang hoặc thư mục mà bot không được phép quét. Trong ví dụ trên, các bot sẽ không quét thư mục
/admin/và/private/.
Ví dụ khi nào cần sử dụng robots.txt:
- Khi bạn muốn ngăn công cụ tìm kiếm lập chỉ mục các trang quản trị như
/admin/,/wp-admin/. - Khi bạn muốn giữ các trang đích hoặc trang thử nghiệm khỏi kết quả tìm kiếm công khai.
- Khi bạn có các tệp tài liệu lớn hoặc nội dung không cần thiết để tiết kiệm tài nguyên cho việc quét.
Dù robots.txt giúp kiểm soát cách các bot truy cập website, nhưng không nên sử dụng nó để bảo vệ thông tin nhạy cảm, vì một số bot không tuân theo và các trang này vẫn có thể được truy cập công khai.
Robots.txt trông như thế nào?
Sau đây là dạng cơ bản của 1 file robots.txt:

Nếu bạn chưa từng thấy một trong những tập tin này trước đây thì nó sẽ trông có vẻ hơi khó nhằn. Tuy nhiên, cú pháp khá đơn giản. Nói tóm lại, bạn đặt ra quy tắc cho các bot bằng cách ghi tên user-agent của chúng rồi theo sau đó là các chỉ thị.
Hãy cùng tìm hiểu về hai phần này cụ thể hơn.
User-agent
Mỗi 1 bộ máy tìm kiếm tự định danh cho nó bằng một user-agent khác nhau. Bạn có thể đặt các chỉ dẫn tùy chỉnh với từng công cụ trong tệp robots.txt của mình. Có hàng trăm user-agent, nhưng sau đây là một số cái tên chuyên dùng cho SEO:
- Google: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
CHÚ Ý BÊN LỀ. Mọi user-agent đều phân biệt chữ hoa và thường trong robots.txt
Bạn cũng có thể sử dụng ký tự sao (*) để gán chỉ thị cho tất cả chúng.
Ví dụ: bạn muốn chặn hết các bot (trừ Googlebot) thu thập dữ liệu site của mình. Và đây là cách mà bạn sẽ làm:

File robots.txt có thể bao gồm các lệnh cho bất cứ user-agent nào mà bạn muốn. Nhưng mỗi khi khai báo 1 user-agent mới, bạn sẽ phải đặt lệnh lại từ đầu một lần nữa. Nói cách khác, nếu bạn thêm nhiều lệnh, chúng sẽ chỉ được áp dụng với bot đầu tiên mà không phải bot thứ hai, thứ ba hay thứ tư, v.v.
Trừ khi bạn khai báo cùng 1 user-agent nhiều lần. Trong trường hợp này, tất cả các lệnh có liên quan sẽ được kết hợp lại và làm theo.
LƯU Ý QUAN TRỌNG
Con bọ chỉ tuân lệnh các chỉ thị được khai báo dưới (những) user-agent được đặt chính xác nhất cho chúng. Đó là lý do tại sao tệp robots.txt ở trên chặn tất cả các bot thu thập dữ liệu (trừ Googlebot và các bot Google khác). Googlebot sẽ bỏ qua khai báo không rõ ràng.
Chỉ thị
Đây là các quy tắc mà bạn muốn user-agent phải tuân theo.
Chỉ thị được hỗ trợ
Sau đây là các chỉ thị mà Google hiện đang hỗ trợ, kèm theo cách dùng của chúng.
Disallow
Sử dụng lệnh này để chỉ thị công cụ tìm kiếm không được phép vào các file và trang web tại một đường dẫn cụ thể. Ví dụ: nếu bạn muốn chặn mọi công cụ truy cập blog và tất cả các bài viết của mình trên đó, tệp robots.txt của bạn có thể là như thế này:

CHÚ Ý BÊN LỀ. Nếu bạn không xác định được đường dẫn để điền sau lệnh disallow, công cụ tìm kiếm sẽ bỏ qua nó.
Allow
Sử dụng lệnh này để cho phép các search engine thu thập dữ liệu thư mục con hoặc từ trang – ngay cả trong 1 thư mục không được phép. Ví dụ: nếu bạn muốn ngăn toàn bộ công cụ truy cập vào mọi bài đăng trên blog của mình ngoại trừ một bài, thì file robots.txt có thể trông như thế này:

Ở ví dụ này, bộ máy tìm kiếm có thể truy cập /blog/allowed-post. Nhưng họ không thể truy cập:
/blog/another-post (bài khác)
/blog/yet-another-post (1 bài khác nữa)
/blog/download-me.pdf
Cả Google và Bing đều hỗ trợ chỉ thị này.
CHÚ Ý BÊN LỀ. Cũng như disallow, nếu bạn không xác định được đường dẫn sau lệnh allow, công cụ tìm kiếm sẽ bỏ qua nó.
Lưu ý các lệnh bị xung đột
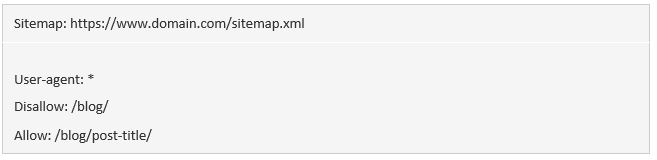
Nếu bạn không cẩn thận, lệnh allow và disallow có thể dễ bị xung đột với nhau. Trong ví dụ dưới đây, chúng ta không cho phép truy cập /blog/ nhưng cho phép truy cập /blog.

Trong trường hợp này, URL /blog/post-title/ dường như không được và được cho phép cùng lúc. Vậy rốt cuộc thì lệnh nào mới có tác dụng?
Đối với Google và Bing, quy luật là: chỉ thị nào có nhiều ký tự nhất thì sẽ có hiệu lực. Ở đây, đó là lệnh disallow.
Disallow: /blog/ (6 ký tự)
Allow: /blog (5 ký tự)
Nếu 2 lệnh có độ dài bằng nhau, thì lệnh ít hạn chế nhất sẽ được áp dụng. Trong trường hợp ấy, đó sẽ là lệnh allow.
CHÚ Ý BÊN LỀ. Ở đây, /blog (không có dấu gạch chéo sau cùng) vẫn có thể được truy cập và thu thập dữ liệu.
Quan trọng là, đây chỉ là trường hợp của Google và Bing. Còn các bộ máy tìm kiếm khác sẽ làm theo chỉ thị khớp đầu tiên. Lúc này, lệnh disallow sẽ có hiệu lực.
Sitemap
Sử dụng lệnh này để nêu rõ vị trí (các) sitemap của bạn với công cụ tìm kiếm. Nếu không biết nhiều về sitemap, bạn có thể hiểu rằng chúng sẽ bao gồm các trang mà bạn muốn search engine thu thập dữ liệu và lập chỉ mục.
Sau đây là ví dụ về 1 file robots.txt bằng chỉ thị sitemap:
Việc có (các) sitemap trong tệp robots.txt quan trọng như thế nào? Nếu bạn đã submit qua Search Console, thì đó sẽ là điều dư thừa với Google. Tuy nhiên, nó vẫn cho các bộ máy tìm kiếm biết nơi để tìm sitemap của bạn, nên nó vẫn có tác dụng.
Cần để ý rằng bạn sẽ không cần phải lặp lại chỉ thị sitemap nhiều lần đối với từng user-agent nữa. Lệnh này không chỉ áp dụng cho duy nhất 1 bot. Do vậy, bạn nên đặt nó ngay đầu hoặc cuối file robots.txt. Ví dụ:
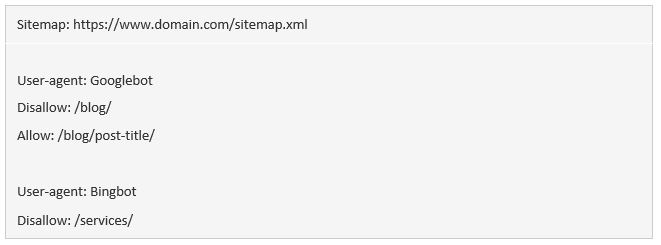
Google hỗ trợ chỉ thị sitemap, cũng như Ask, Bing, và Yahoo.
CHÚ Ý BÊN LỀ. Bạn có thể để nhiều sitemap mà bạn muốn trong file robots.txt.
Chỉ thị không được hỗ trợ
Những chỉ thị dưới đây không còn được Google hỗ trợ nữa – chính xác thì, 1 số lệnh còn chưa bao giờ được hỗ trợ.
Crawl-delay
Trước đây, bạn có thể sử dụng lệnh này để chỉ định thời gian trước mỗi lần bot thu thập dữ liệu. Ví dụ, nếu bạn muốn Googlebot đợi 5 giây trước khi crawl tiếp, bạn sẽ đặt lệnh là 5 như thế này:

Google không còn hỗ trợ lệnh này nữa, nhưng Bing và Yandex thì vẫn.
Điều này cho thấy, bạn cần cẩn thận với lệnh này, đặc biệt là nếu bạn có 1 site lớn. Khi đặt 1 lệnh crawl-delay 5 giây, thì tức là bạn đang hạn chế các bot crawl với nhiều nhất là 17,280 URLs 1 ngày. Nó sẽ không có ích nếu bạn có vài triệu trang, nhưng bạn vẫn có thể tiết kiệm được băng thông khi có 1 website nhỏ.
Noindex
Lệnh này chính thức chưa bao giờ được Google hỗ trợ. Tuy nhiên, mãi cho đến gần đây, Google được cho là có 1 vài “code có thể xử lý được các quy tắc được và không được hỗ trợ (ví dụ noindex)”. Vậy nếu muốn ngăn Google lập chỉ mục tất cả các bài trên blog, bạn có thể sử dụng lệnh sau:

Tuy nhiên, vào 01/09/2019, Google đã nói rõ lệnh này không hề được hỗ trợ. Nếu bạn muốn chặn 1 trang hoặc file khỏi các search engine, hãy thay thế bằng cách sử dụng thẻ meta robots hoặc x-robots HTTP header.
Nofollow
Đây là 1 chỉ thị khác mà Google hoàn toàn không hỗ trợ, và được dùng để chỉ định bộ máy tìm kiếm không được đi theo các link trên những trang và file ở 1 đường dẫn cụ thể. Ví dụ, nếu không muốn cho Google crawl tất cả link trên blog, bạn có thể dùng lệnh sau:

Google đã tuyên bố rõ rằng lệnh này không được hỗ trợ vào ngày 01/09/2019. Nếu bây giờ bạn muốn đặt lệnh nofollow mọi link trên 1 trang, bạn nên sử dụng thẻ meta hoặc x-robots header. Nếu muốn Google không đi theo những link cụ thể trên 1 trang, dùng thuộc tính rel=”nofollow”.
Liệu bạn có cần tới file robots.txt?
Việc có 1 file robots.txt sẽ không quan trọng lắm đối với nhiều website, đặc biệt là những web nhỏ.
Nhưng không có gì là không tốt nếu có 1 tệp. Nó giúp bạn kiểm soát được nơi các search engine có thể và không thể đi được trên website của mình, và điều đó có thể giúp:
- Ngăn trình việc thu thập dữ liệu nội dung trùng lặp;
- Giữ kín các phần của website (ví dụ: staging site của bạn);
- Chặn việc thu thập dữ liệu của các trang kết quả tìm kiếm nội bộ;
- Ngăn máy chủ bị quá tải;
- Đề phòng Google khỏi bị lãng phí “crawl budget” (tài nguyên để thu thập dữ liệu).
- Ngăn chặn các tập tin hình ảnh, video và tài nguyên xuất hiện trong kết quả tìm kiếm của Google.
Lưu ý rằng mặc dù Google thường không index các trang web bị chặn trong robots.txt, nhưng không có cách nào sẽ đảm bảo được việc loại những trang đó khỏi kết quả tìm kiếm bằng tệp này.
Giống như Google cho biết, nếu content được liên kết từ các nơi khác trên web, nó vẫn có thể xuất hiện trong kết quả tìm kiếm của Google.
Cách để tìm file robots.txt của bạn
Nếu bạn đã có tệp robots.txt trên website của mình, nó sẽ có thể truy cập được tại domain.com/robots.txt. Điều hướng đến URL trong trình duyệt của bạn. Nếu bạn thấy một cái gì đó như thế này, thì nghĩa là bạn có tệp robots.txt:

Làm thế nào để tạo tệp robots.txt
Nếu bạn chưa có file robots.txt thì đừng lo, bởi cách tạo rất dễ. Chỉ cần mở một tài liệu trống .txt và bắt đầu nhập các chỉ thị. Ví dụ: nếu bạn không cho phép tất cả các công cụ tìm kiếm thu thập dữ liệu thư mục /admin/của bạn, nó sẽ trông giống như thế này:

Tiếp tục xây dựng các lệnh cho đến khi bạn thấy ổn với những gì mình có. Lưu tệp của bạn dưới dạng “robots.txt”.
Ngoài ra, bạn cũng có thể tạo robots.txt qua công cụ này.
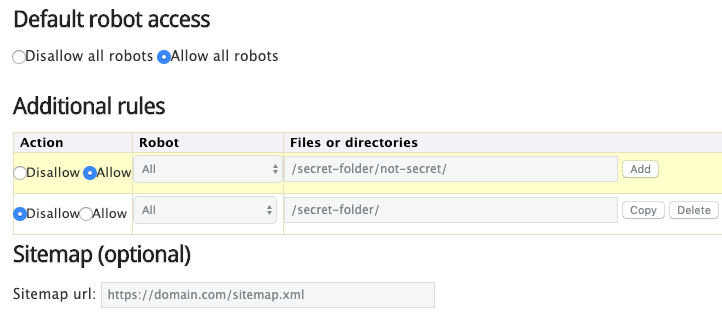
Ưu điểm của nó là giảm thiểu được các lỗi cú pháp. Điều này khá là tốt vì một sai lầm sẽ có thể dẫn đến việc SEO trang web của bạn bị hủy hoại.
Còn nhược điểm là chúng sẽ có phần hạn chế về khả năng tùy chỉnh.
Nơi để file robots.txt của bạn
Hãy đặt tệp robots.txt của bạn trong thư mục gốc của tên miền phụ. Ví dụ: để kiểm soát trình crawl trên domain.com, tệp này nên được truy cập tại domain.com/robots.txt.
Nếu bạn muốn kiểm soát việc thu thập thông tin trên một tên miền phụ như blog.domain.com, thì nó nên được truy cập tại blog.domain.com/robots.txt.
Các lỗi điển hình nhất của Robots.txt
Hãy nhớ để tránh những sai lầm phổ biến sau.
Sử dụng một dòng mới cho từng chỉ thị
Mỗi lệnh nên được để ở 1 dòng mới. Nếu không, nó sẽ làm các search engine bị rối.
Không nên:

Nên:

Sử dụng ký tự đại diện để đơn giản hóa chỉ dẫn
Bạn không chỉ có thể sử dụng ký tự đại diện (*) để áp dụng các lệnh cho tất cả user-agent, mà còn các mẫu URL khi khai báo chúng. Ví dụ: nếu muốn ngăn bộ máy tìm kiếm truy cập các URL parameter (phần theo sau dấu?) của danh mục sản phẩm trên site của mình, bạn có thể liệt kê chúng ra như sau:

Nhưng cách đó không hiệu quả lắm. Sẽ tốt hơn nếu đơn giản hóa mọi thứ với một ký tự đại diện như thế này:

Ví dụ này chặn các công cụ thu thập dữ liệu tất cả URL sau thư mục con của /product/ chứa dấu hỏi. Nói cách khác, bất kỳ URL parameter của danh mục sản phẩm.
Sử dụng “$”để chỉ định kết thúc URL
Hãy đặt biểu tượng “$” để đánh dấu sự kết thúc của một URL. Ví dụ: nếu bạn muốn ngăn search engine truy cập tất cả file .pdf trên site của mình, tệp robots.txt của bạn có thể sẽ thế này:

Trong ví dụ này, các bộ máy tìm kiếm không thể truy cập vào bất kỳ URL nào có đuôi là .pdf. Điều đó có nghĩa là họ không thể truy cập /file.pdf, nhưng lại có thể tới /file.pdf?id=68937586 bởi nó không kết thúc với “.pdf”.
Sử dụng mỗi user-agent một lần
Nếu bạn chỉ định cùng một user-agent nhiều lần, Google sẽ không bận tâm. Nó sẽ chỉ đơn thuần kết hợp tất cả lệnh từ những khai báo khác nhau thành một và tuân theo chúng. Ví dụ: nếu bạn có user-agent và chỉ thị này trong tệp robots.txt…

… Google sẽ không thực hiện crawl cả 2 thư mục con đó.
Nhưng bạn nên khai báo mỗi user-agent chỉ một lần vì nó sẽ ít gây nhầm lẫn hơn. Nói cách khác, bạn sẽ ít có khả năng bị mắc lỗi nghiêm trọng bằng cách giữ mọi thứ gọn gàng và đơn giản.
Chú ý sự chi tiết để tránh các lỗi vô ý
Việc không cung cấp hướng dẫn cụ thể khi thiết lập chỉ thị có thể dẫn đến các lỗi dễ bị bỏ qua. Nó sẽ gây ra 1 sự ảnh hưởng nghiêm trọng đối với SEO. Ví dụ: hãy giả sử rằng bạn có 1 site đa ngôn ngữ và bạn đang làm trên một phiên bản tiếng Đức có sẵn sau thư mục con /de/.
Do vẫn chưa hoàn thiện, nên bạn muốn ngăn công cụ tìm kiếm truy cập nó.
Tệp robots.txt dưới đây sẽ chặn chúng tới thư mục con đó và mọi thứ trong này:

Nhưng nó sẽ vẫn ngăn các bộ máy thu thập bất cứ trang hoặc file nào mà bắt đầu với /de.
Ví dụ:
/designer-dresses/
/delivery-information.html
/depeche-mode/t-shirts/
/definitely-not-for-public-viewing.pdf
Trong ví dụ này, cách giải quyết đơn giản đó là: thêm 1 dấu gạch chéo sau cùng.

Dùng comment để giải thích tệp robots.txt cho chính con người
Nhận xét giúp giải thích tệp robots.txt của bạn cho các developer và thậm chí cả chính bạn trong tương lai nữa. Để đặt một nhận xét, hãy bắt đầu dòng với dấu #.

Con bọ sẽ bỏ qua mọi thứ khi có dấu này.
Dùng tệp robots.txt riêng cho từng subdomain
Robots.txt chỉ kiểm soát việc thu thập thông tin trên tên miền phụ nơi nó được lưu trữ. Nếu bạn muốn quản lý nó trên một tên miền phụ khác, bạn sẽ cần một tệp robots.txt riêng.
Ví dụ: nếu site chính của bạn là domain.com và trang blog ở blog.domain.com, thì bạn sẽ cần hai file robots.txt. Một cái nên vào thư mục gốc của tên miền chính, và cái kia trong thư mục gốc của blog.
Ví dụ file robots.txt
Dưới đây là một vài ví dụ về các file này. Chúng chủ yếu là để truyền cảm hứng nhưng nếu một trong số đó phù hợp với yêu cầu của bạn, hãy copy-paste vào một tài liệu văn bản, lưu nó dưới dạng “robots.txt” và tải nó lên thư mục thích hợp.
Truy cập toàn quyền cho tất cả các bot

CHÚ Ý BÊN LỀ. Không thể khai báo URL khi chỉ thị đó bị sai hoặc dư thừa. Nói cách khác, công cụ tìm kiếm sẽ bỏ qua nó. Đó là lý do tại sao chỉ thị disallow này không có hiệu lực trên site. Các search engine vẫn có thể thu thập dữ liệu mọi trang và tệp.
Không cấp quyền truy cập cho mọi bot

Chặn 1 thư mục con đối với tất cả bot

Chặn 1 thư mục con với toàn bộ bot (với 1 file cho phép trong đó)

Chặn 1 file với tất cả bot

Chặn 1 dạng file (ví dụ PDF) cho mọi bot

Chặn các URL parameter với duy nhất Googlebot

Cách audit những lỗi trong file robots.txt của bạn
Các lỗi trong robots.txt có thể khá dễ bị vô tình bỏ qua, do vậy bạn cần phải cẩn thận chú ý với mọi vấn đề.
Thường xuyên kiểm tra các sự cố liên quan đến robots.txt trong báo cáo “Coverage” ở Search Console. Dưới đây là một số lỗi bạn có thể sẽ gặp phải. Hãy tìm hiểu xem chúng là gì và cách bạn có thể sửa chúng.
Cần kiểm tra các lỗi của 1 trang cụ thể?
Dán URL vào công cụ Google’s URL Inspection trong Search Console. Nếu nó bị chặn bởi robots.txt, bạn sẽ thấy một cái gì đó giống thế này:
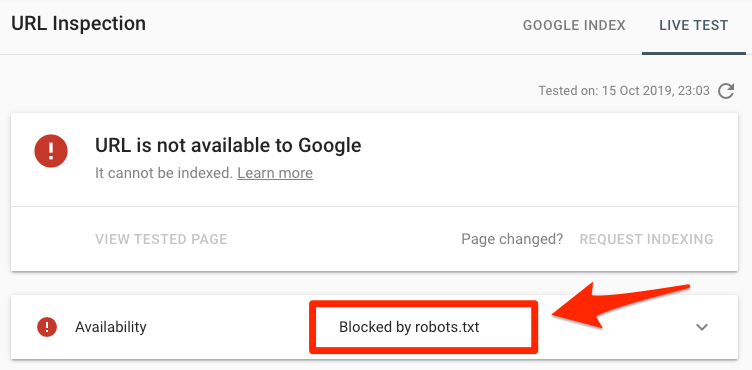
URL đã submit bị chặn bởi robots.txt
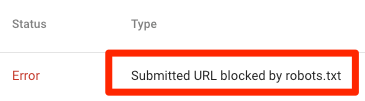
Ít nhất một trong số các URL ở (các) sitemap đã submit của bạn bị chặn trong tệp robots.txt.
Nếu bạn đã tạo đúng sơ đồ trang web của mình và loại trừ các trang gắn thẻ canonical, noindex, và redirect, thì sẽ không có trang đã submit nào bị chặn bởi robots.txt. Nếu có, hãy tìm hiểu các trang có vấn đề, sau đó điều chỉnh tệp robots.txt của bạn để loại bỏ những lỗi đó.
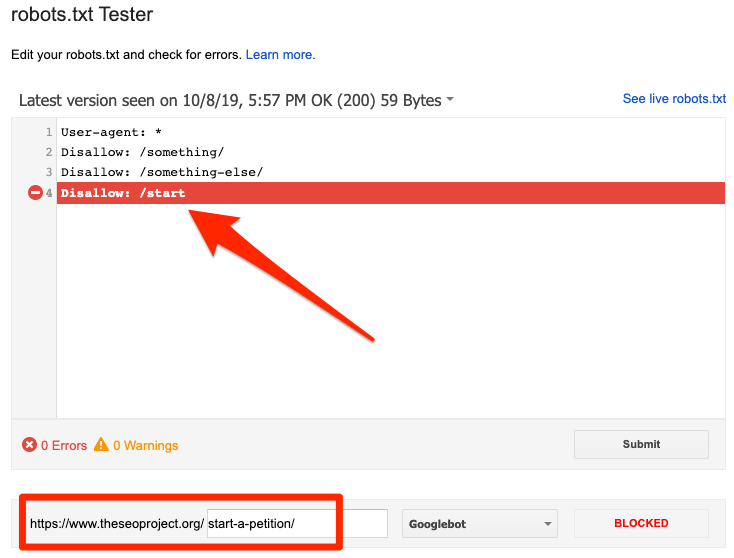
Bạn có thể sử dụng trình kiểm tra robots.txt của Google để xem lệnh nào đang chặn nội dung. Hãy cẩn thận khi thực hiện quá trình này. Bạn sẽ rất dễ bị mắc lỗi và từ đó có thể làm ảnh hưởng các trang và file khác nữa.
Bị chặn bởi robots.txt
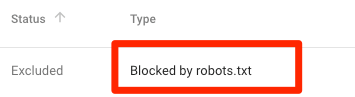
Như thế này tức là bạn có nội dung bị chặn bởi robots.txt nên hiện đang không được Google index.
Nếu nội dung ấy quan trọng và cần được lập chỉ mục, hãy xóa lệnh chặn crawl trong tệp robots.txt. (Sẽ tốt hơn nếu đảm bảo rằng nội dung được index). Nếu bạn đã chặn nội dung trong file này với mục đích loại nó khỏi chỉ mục của Google, hãy xóa lệnh đó và sử dụng thẻ meta robots hoặc x-robots-header thay thế. Đây là cách duy nhất để đảm bảo không cho Google index content.
CHÚ Ý BÊN LỀ. Việc xóa lệnh chặn khi cố gắng loại trừ một trang khỏi kết quả tìm kiếm là rất quan trọng. Nếu thất bại, và Google không thấy thẻ noindex hoặc HTTP header – nội dung vẫn sẽ được lập chỉ mục.
Vẫn bị index, dù đã chặn trong robots.txt
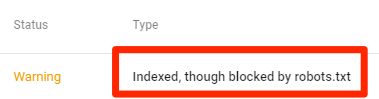
Như vậy nghĩa là một số nội dung dù bị chặn bởi file robots.txt vẫn được lập chỉ mục trong Google.
Một lần nữa, nếu bạn đang cố gắng loại trừ nó khỏi kết quả tìm kiếm của Google, thì tệp robots.txt sẽ không phải là 1 giải pháp. Xóa lệnh chặn crawl và thay vào đó sử dụng thẻ meta robots hoặc HTTP header x-robots-tag để ngăn index.
Nếu bạn vô tình chặn nó và muốn giữ trong chỉ mục Google, hãy xóa lệnh chặn trong tệp robots.txt. Điều này có thể giúp cải thiện khả năng hiển thị của nội dung trong trang tìm kiếm của Google.
Câu hỏi thường gặp
Dưới đây là một vài câu hỏi thường gặp mà chưa có trong bài hướng dẫn trên của chúng tôi. Hãy comment cho chúng tôi biết nếu thiếu bất cứ điều gì để tiếp tục cập nhật bổ sung.
Dung lượng tối đa của một tập tin robots.txt là bao nhiêu?
(Khoảng) 500 kilobyte.
Robots.txt ở đâu trong WordPress?
Cùng 1 chỗ: domain.com/robots.txt.
Làm cách nào để chỉnh sửa robots.txt trong WordPress?
Bạn có thể chỉnh thủ công hoặc sử dụng một trong những plugin SEO của WordPress như Yoast cho phép bạn sửa robots.txt từ WordPress backend.
Điều gì xảy ra nếu tôi không cho phép truy cập vào nội dung noindex trong tệp robots.txt?
Google sẽ không bao giờ thấy lệnh noindex bởi nó không thể thu thập dữ liệu của trang đó.
Kết luận cuối
Robots.txt tuy chỉ là một file đơn giản nhưng lại có 1 tầm quan trọng nhất định. Nếu sử dụng một cách khôn ngoan, nó sẽ đem tới tác động tích cực cho quá trình SEO của bạn. Còn nếu không cẩn thận, bạn sẽ phải hối tiếc.
Nguồn : https://ahrefs.com/blog/robots-txt/
Dịch bởi Phương Thanh

Tôi là Lê Hưng, là Founder và CEO của SEO VIỆT, với hơn 14 năm kinh nghiệm trong lĩnh vực SEO. Dưới sự lãnh đạo của tôi, SEO VIỆT đã xây dựng uy tín vững chắc và trở thành đối tác tin cậy của nhiều doanh nghiệp. Tôi còn tích cực chia sẻ kiến thức và tổ chức các sự kiện quan trọng, đóng góp vào sự phát triển của cộng đồng SEO tại Việt Nam.





Bài viết liên quan
Cấu trúc Silo là gì? Hướng dẫn thiết lập Silo Structure cho Website
Bạn đã bao giờ rơi vào tình trạng: Đổ hàng đống tiền viết hàng trăm...
Hướng dẫn đổi tên miền Website giữ nguyên Traffic & Thứ hạng SEO
Quyết định đổi tên miền luôn đi kèm với sự lo lắng tột độ. Chúng...
Semantic Search là gì? Cẩm nang Tối ưu Tìm kiếm Ngữ nghĩa trong SEO
Kỷ nguyên của những bài viết nhồi nhét từ khóa một cách máy móc đã...
Topic Cluster là gì? Cách triển khai Topic Cluster hiệu quả
Topic Cluster không chỉ là kỹ thuật nhóm bài viết mà là phương thức xây...
Lỗi 404 Not Found là gì? 6 nguyên nhân và quy trình xử lý
Nếu bạn từng lướt web và bắt gặp thông báo “404 Not Found”, chắc hẳn...
Orphan Pages (trang mồ côi) là gì? Cách tìm và khắc phục
Orphan Pages hay còn gọi là các trang mồ côi, là một thuật ngữ quen...
Cách tối ưu bài viết chuẩn EEAT SEO
EEAT là trọng số ngày càng quan trọng sau các đợt Core Update của Google....
SEO tổng thể là gì? Quy trình triển khai SEO tổng thể bền vững
Thuật toán Google liên tục thay đổi khiến hàng loạt website SEO “mũ đen” lao...
Hướng dẫn tăng tốc độ Website toàn tập: X10 Tốc độ chỉ trong 5 Phút
Bạn có biết 40% người dùng sẽ thoát trang ngay lập tức nếu một website...