Bạn vừa xây dựng xong một website tuyệt đẹp, nhưng liệu Google có biết chính xác nên “đọc” những phần nào và bỏ qua những trang hệ thống không? Đây là lúc bạn cần đến file robots.txt. Hiểu đơn giản, tệp tin này đóng vai trò như một người gác cổng, hướng dẫn các công cụ tìm kiếm cách thu thập dữ liệu trên trang web của bạn một cách hiệu quả. Trong bài viết này, tôi sẽ giúp bạn hiểu rõ robots.txt là gì, cách cấu hình chuẩn SEO và cung cấp sẵn 3 file mẫu cho các nền tảng CMS phổ biến để bạn có thể áp dụng ngay lập tức.

Robots.txt là gì?
Robots.txt là một tập tin văn bản thuần túy (.txt) tuân theo Tiêu chuẩn loại trừ Robot (Robots Exclusion Standard). Nó đóng vai trò như một bảng nội quy dành riêng cho các phần mềm tự động (bot) từ Google, Bing hay Yahoo.
Khi một web crawler truy cập vào trang của bạn, việc đầu tiên nó làm là tìm đọc file này. Thông qua các dòng lệnh đơn giản, bạn đang giao tiếp trực tiếp với bot, báo cho chúng biết trang nào được phép và trang nào không được phép thu thập dữ liệu (crawl).
Vị trí của file robots.txt trên website
Để các công cụ tìm kiếm có thể quét thấy bảng nội quy này, file robots.txt bắt buộc phải nằm ở thư mục gốc (root directory) của website. Nếu bạn đặt nó ở bất kỳ thư mục con nào khác, bot sẽ mặc định coi như trang web của bạn không có tệp này.
Cách kiểm tra thực tế rất đơn giản. Bạn chỉ cần gõ tên miền của mình lên trình duyệt và thêm hậu tố /robots.txt vào phía sau.
Ví dụ minh họa:
[https://domain.com/robots.txt]
Nếu trang web đã được cấu hình đúng, bạn sẽ nhìn thấy ngay các dòng lệnh phân quyền (User-agent, Allow, Disallow) xuất hiện trên màn hình. Nếu bạn đang gặp khó khăn trong việc tìm kiếm file này, đội ngũ kỹ thuật của chúng tôi luôn sẵn sàng hỗ trợ bạn kiểm tra lại cấu trúc thư mục.
Vai trò của robots.txt trong SEO
Việc thiết lập file robots.txt không chỉ đơn thuần là phân quyền truy cập. Đây là một kỹ thuật tối ưu On-page giúp bảo vệ tài nguyên máy chủ, quản lý ngân sách quét trang và nâng cao hiệu suất SEO tổng thể của chiến dịch.
Quản lý Crawl Budget
Crawl Budget (Ngân sách thu thập dữ liệu) là số lượng trang mà Googlebot quyết định thu thập trên website của bạn trong một khoảng thời gian nhất định. Mức ngân sách này có giới hạn và phụ thuộc vào sức khỏe máy chủ cũng như độ uy tín của website.
Đối với các website quy mô lớn như nền tảng thương mại điện tử có hàng chục ngàn URL, quản lý Crawl Budget là ưu tiên hàng đầu. Bằng cách chặn bot khỏi các trang kém quan trọng (trang giỏ hàng, URL chứa tham số bộ lọc), bạn sẽ dồn toàn bộ ngân sách này cho những landing page mang lại giá trị chuyển đổi cao.
Điều hướng Web Crawler
Một website luôn tồn tại những khu vực dữ liệu nội bộ mà bạn không muốn phơi bày ra ngoài kết quả tìm kiếm. Đó có thể là trang đăng nhập quản trị admin, trang kết quả tìm kiếm nội bộ, hay các bài viết đang trong quá trình thử nghiệm.
Lúc này, lệnh Disallow trong robots.txt sẽ đóng vai trò như một biển cấm đi vào. Nó điều hướng Web Crawler tránh xa các khu vực nhạy cảm này, đảm bảo chúng không bị lập chỉ mục và rò rỉ trên Google, giúp bảo vệ cấu trúc thông tin của bạn.
Ngăn chặn quá tải Server
Mỗi lần một con bot quét trang để đọc dữ liệu, nó sẽ gửi một yêu cầu đến máy chủ của bạn. Nếu hàng loạt bot từ nhiều công cụ tìm kiếm khác nhau cùng ồ ạt thu thập dữ liệu, server hoàn toàn có thể bị quá tải, dẫn đến tình trạng sập mạng.
Sử dụng lệnh Crawl-delay trong robots.txt cho phép bạn kiểm soát tốc độ quét của bot. Bằng cách quy định khoảng thời gian giãn cách giữa các lần thu thập (ví dụ: 10 giây một lần), máy chủ của bạn sẽ luôn hoạt động ổn định, duy trì tốc độ tải trang mượt mà cho các khách hàng thực tế đang mua sắm.
Cú pháp của file robots.txt
Mỗi tệp robots.txt được cấu thành từ các nhóm lệnh riêng biệt. Để bạn dễ hình dung cách chúng tương tác với nhau, chúng tôi đã tóm tắt các cú pháp phổ biến nhất qua bảng dưới đây:
| Lệnh khai báo | Chức năng chính | Tác động đến Web Crawler |
|---|---|---|
| User-agent | Xác định đối tượng nhận lệnh | Gọi đích danh một con bot hoặc áp dụng cho toàn bộ bot |
| Disallow | Chặn quyền truy cập | Cấm bot tiến vào thu thập dữ liệu tại đường dẫn được chỉ định |
| Allow | Cấp quyền truy cập ngoại lệ | Cho phép bot vào quét một tệp/thư mục nằm trong vùng đã bị chặn |
| Sitemap | Chỉ dẫn bản đồ website | Cung cấp toàn bộ cấu trúc URL để bot quét trang nhanh hơn |
User-agent
Lệnh đầu tiên luôn xuất hiện trong mọi cấu hình robots.txt chính là User-agent. Đây là cách bạn gọi tên đích danh “vị khách” mà mình muốn áp dụng quy tắc.
Bạn có thể nhắm mục tiêu cụ thể đến từng loại bot như Googlebot (của Google) hay Bingbot (của Microsoft). Nếu muốn áp dụng một quy tắc chung cho toàn bộ các công cụ tìm kiếm, bạn chỉ cần sử dụng dấu hoa thị * đại diện cho tất cả.
Disallow
Sau khi đã xác định được đối tượng, bạn sẽ dùng lệnh Disallow để thiết lập vùng cấm. Lệnh này báo cho bot biết những thư mục hoặc đường dẫn URL nào không được phép quét dữ liệu.
Ví dụ, bạn có thể thiết lập Disallow: /wp-admin/ để che giấu trang đăng nhập nội bộ. Bất kỳ đường dẫn nào nằm sau lệnh này đều sẽ bị các trình thu thập dữ liệu bỏ qua ngay lập tức.
Allow
Mặc định, bot được phép truy cập vào mọi nơi trên website trừ khi bị chặn. Vậy tại sao chúng ta lại cần lệnh Allow? Lệnh này thường được dùng để tạo ra một ngoại lệ cấp phép ngay bên trong một thư mục đã bị Disallow.
Giả sử bạn chặn bot quét toàn bộ thư mục /images/, nhưng lại muốn Google lập chỉ mục riêng một bức ảnh sản phẩm quan trọng trong đó. Bạn sẽ dùng lệnh Allow: /images/san-pham-a.jpg để mở một “lối đi nhỏ” xuyên qua bức tường rào đã dựng sẵn.
Sitemap
Không chỉ mang tính chất cấm cản, robots.txt còn là một công cụ dẫn đường tuyệt vời. Bằng cách khai báo đường dẫn Sitemap ở cuối file, bạn đang trao tận tay bản đồ dữ liệu cho các crawler.
Ngay khi bot truy cập vào website, chúng sẽ đọc dòng lệnh này và nắm được toàn bộ cấu trúc liên kết của bạn. Điều này giúp quá trình khám phá các bài viết mới diễn ra nhanh chóng và triệt để hơn rất nhiều.
Sự khác biệt giữa robots.txt và meta robots
Rất nhiều người quản trị website thường nhầm lẫn giữa việc chặn quét dữ liệu (crawl) và chặn lập chỉ mục (index). Để hiển thị dữ liệu chính xác trên Google, bạn bắt buộc phải phân biệt rõ ràng hai khái niệm này.
Cơ chế hoạt động của robots.txt
Như đã phân tích, lệnh Disallow trong robots.txt là một bảng nội quy đặt ở cửa máy chủ. Nhiệm vụ duy nhất của nó là ngăn bot tiến vào đọc nội dung trang (chặn crawl).
Tuy nhiên, nó không đảm bảo URL đó sẽ hoàn toàn biến mất khỏi Google. Nếu một website khác trỏ liên kết (backlink) về URL đang bị chặn, công cụ tìm kiếm vẫn biết trang đó tồn tại. Kết quả là URL này vẫn có thể xuất hiện trên bảng xếp hạng, nhưng thiếu đi phần đoạn trích mô tả.
Cơ chế hoạt động của meta robots noindex
Ngược lại với robots.txt, thẻ meta robots được nhúng trực tiếp vào thẻ <head> trong mã nguồn HTML của từng trang cụ thể. Lệnh “noindex” cho phép bot thoải mái quét dữ liệu, nhưng cấm tuyệt đối việc lưu trữ trang đó vào cơ sở dữ liệu tìm kiếm.
Đây là phương pháp kỹ thuật chắc chắn nhất để loại bỏ một trang ra khỏi Google. Bot vẫn đọc được nội dung, nhưng nó buộc phải tuân thủ lệnh không hiển thị dữ liệu này cho người dùng tìm kiếm.
Ứng dụng thực tế
Tùy thuộc vào thực trạng website, việc lựa chọn phương án can thiệp sẽ thay đổi. Dưới đây là cách chúng tôi linh hoạt áp dụng trên các dự án quản trị:
Sử dụng robots.txt khi: Bạn cần tiết kiệm ngân sách thu thập dữ liệu, giảm tải request cho máy chủ, hoặc che giấu hàng loạt thư mục hệ thống (file script, plugin).
Sử dụng thẻ meta noindex khi: Bạn muốn xóa sổ hoàn toàn một URL khỏi bộ máy tìm kiếm (ví dụ: trang cảm ơn sau khi điền form, trang nội dung mỏng) nhưng người dùng có sẵn link vẫn có thể truy cập bình thường.
Các bước tạo và cấu hình file robots.txt
Để đảm bảo tính chính xác và tránh các lỗi cú pháp không đáng có, chúng tôi đã chia nhỏ quy trình thành ba giai đoạn cơ bản. Bạn chỉ cần làm theo đúng trình tự dưới đây để đưa bảng nội quy này lên môi trường internet.
Tạo file robots.txt bằng Text Editor
Robots.txt bắt buộc phải được lưu dưới định dạng văn bản thuần túy. Bạn tuyệt đối không sử dụng Microsoft Word hay các phần mềm soạn thảo phức tạp vì chúng sẽ tự động chèn thêm các mã định dạng ẩn gây lỗi hệ thống.
Công cụ tốt nhất và nhẹ nhất có sẵn trên mọi máy tính Windows chính là Notepad. Cách thao tác vô cùng đơn giản:
Mở phần mềm Notepad trên hệ điều hành của bạn.
Nhập các dòng lệnh (User-agent, Disallow, Allow) tùy theo chiến lược bảo mật nội dung.
Lưu tập tin với tên chính xác là
robots.txt(lưu ý viết thường toàn bộ và đảm bảo đuôi file là.txt).
Tải file lên thư mục gốc (Root directory)
Sau khi có được tập tin hoàn chỉnh, bạn cần đưa nó lên không gian lưu trữ của máy chủ. Vị trí duy nhất mà các công cụ tìm kiếm sẽ tìm đọc là thư mục gốc, thường được đặt tên là public_html hoặc www.
Nếu bạn quen sử dụng phần mềm giao thức FTP/SFTP (như FileZilla), hãy kết nối với máy chủ và kéo thả file vừa tạo vào ngay thư mục ngoài cùng. Tệp này sẽ nằm cùng cấp với các tệp tin vận hành website như index.php.
Trong trường hợp thao tác trực tiếp trên trình duyệt, hãy đăng nhập vào hệ thống cPanel. Mở công cụ File Manager, nhấp chọn public_html và sử dụng tính năng Upload trên thanh công cụ để tải file robots.txt lên máy chủ.
Khai báo robots.txt trên nền tảng quản trị hosting
Nhiều nhà cung cấp hosting hiện nay tích hợp sẵn các công cụ hỗ trợ SEO ngay trong bảng điều khiển (control panel). Việc khai báo tại đây giúp máy chủ cập nhật nhanh chóng và chính xác các quy tắc bạn vừa thiết lập.
Bạn hãy tìm đến mục quản lý File hoặc các tiện ích bổ sung (SEO Tools) trên giao diện hosting. Kiểm tra lại một lần nữa bằng cách nhấp thẳng vào đường dẫn tệp để xem hệ thống đã nhận diện đúng định dạng văn bản thuần túy hay chưa.
Mẫu file robots.txt cho CMS
Mỗi nền tảng quản trị nội dung sở hữu một cấu trúc thư mục đặc thù. Thay vì phải tự nghiên cứu và viết lại từ đầu, bạn hoàn toàn có thể sao chép các đoạn mã chuẩn SEO mà chúng tôi đã thiết kế sẵn dưới đây.
Mẫu file cho WordPress
Mã nguồn WordPress chứa một thư mục quản trị mà bạn tuyệt đối không muốn phơi bày trên kết quả tìm kiếm là /wp-admin/. Tuy nhiên, bạn phải mở khóa tệp admin-ajax.php để các plugin và giao diện bên thứ ba hoạt động trơn tru.
Dưới đây là đoạn mã tiêu chuẩn tối ưu nhất dành cho website WordPress:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://domaincuaban.com/sitemap_index.xml
Mẫu file cho Shopify
Shopify là nền tảng thương mại điện tử khép kín, vì vậy việc bảo mật chu trình mua sắm là ưu tiên hàng đầu. Bạn cần chặn bot thu thập dữ liệu tại khu vực giỏ hàng, trang thanh toán và lịch sử đơn hàng của người dùng.
Hãy sử dụng cấu hình này để bảo vệ dữ liệu và tối ưu hóa ngân sách thu thập:
User-agent: * Disallow: /admin Disallow: /cart Disallow: /orders Disallow: /checkout Disallow: /411215/policies/ Sitemap: https://domaincuaban.com/sitemap.xml
Mẫu file cho Haravan
Tương tự như Shopify, hệ thống của Haravan cũng yêu cầu bảo mật thông tin giao dịch cá nhân nghiêm ngặt. Các lệnh dưới đây sẽ ngăn chặn rò rỉ dữ liệu tìm kiếm nội bộ và thông tin tài khoản khách hàng.
Chỉ cần thay đổi tên miền của bạn vào dòng cuối cùng và sử dụng đoạn mã này:
User-agent: * Disallow: /admin Disallow: /cart Disallow: /checkout Disallow: /account Disallow: /search Sitemap: https://domaincuaban.com/sitemap.xml
Quy trình kiểm tra robots.txt trên Google Search Console
Thay vì ngồi đoán xem bot có đọc đúng ý mình hay không, Google Search Console cung cấp một bộ công cụ giúp bạn nhìn website dưới góc độ của một công cụ tìm kiếm.
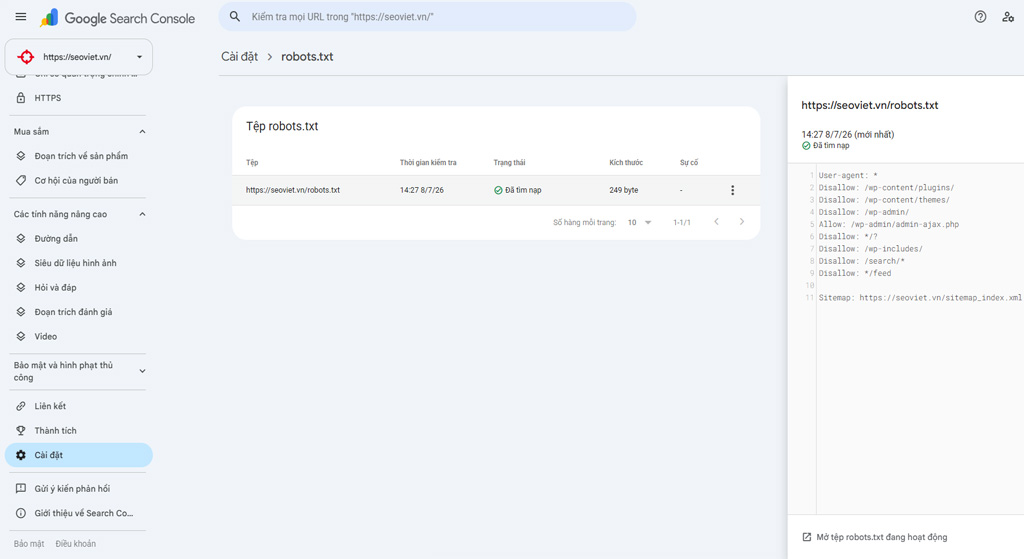
Truy cập công cụ kiểm tra robots.txt
Trong giao diện Search Console mới, báo cáo quản lý tệp này đã được tích hợp thẳng vào mục Cài đặt (Settings). Tại đây, Google sẽ hiển thị chính xác phiên bản tập tin mà hệ thống của họ đang lưu trữ trong bộ nhớ tạm, kèm theo thời gian quét gần nhất và trạng thái thu thập.
Nếu bạn vừa chỉnh sửa file trên máy chủ, hãy nhấp vào biểu tượng ba chấm và chọn Yêu cầu thu thập lại (Request a recrawl) để ép Google cập nhật bảng nội quy mới ngay lập tức, thay vì phải chờ đợi theo lịch trình tự động của họ.
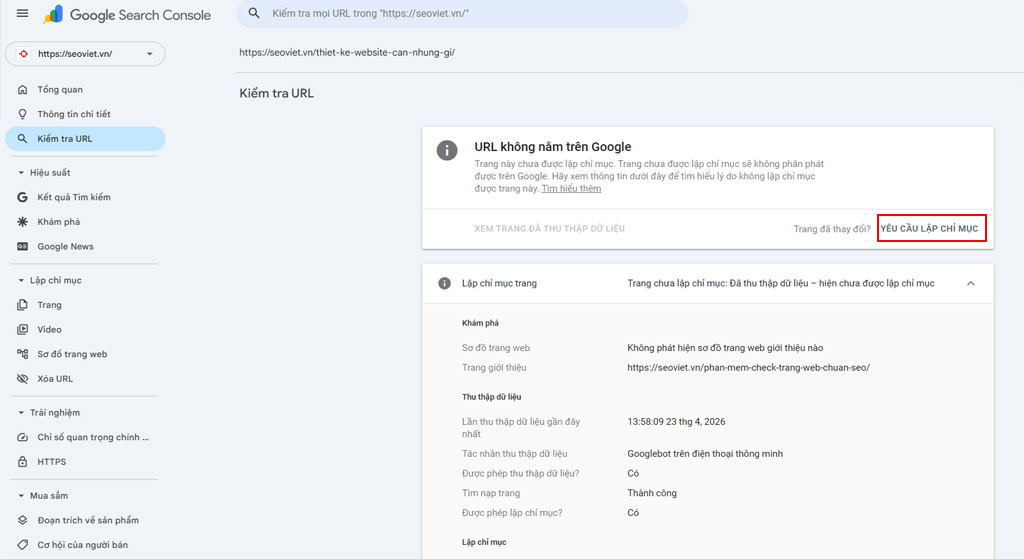
Đọc báo cáo Lập chỉ mục trang
Công cụ kiểm tra ở phần Cài đặt chỉ xác nhận việc tệp có tồn tại và truy cập được hay không. Để đo lường hiệu quả thực tế của các lệnh Disallow, bạn phải theo dõi tab Lập chỉ mục (Indexing) > Trang (Pages).
Báo cáo này liệt kê chi tiết từng URL đang gặp vấn đề trên website. Chúng tôi khuyến nghị bạn nên thường xuyên kiểm tra khu vực này để phát hiện sớm các URL bị chặn nhầm, đảm bảo những trang đích (landing page) quan trọng luôn trong trạng thái sẵn sàng xuất hiện trên kết quả tìm kiếm.
Xử lý cảnh báo “Bị chặn bởi robots.txt”
Đây là một trong những cảnh báo gây hoang mang nhất cho người làm cấu trúc website. Cảnh báo Đã lập chỉ mục, mặc dù bị chặn bởi robots.txt (Indexed, though blocked by robots.txt) xuất hiện khi bạn chặn bot quét một URL, nhưng URL đó lại có một liên kết (backlink) trỏ về từ trang web khác. Kết quả là Google vẫn biết trang đó tồn tại và quyết định đưa nó lên kết quả tìm kiếm, chỉ là không hiển thị mô tả thẻ meta (snippet).
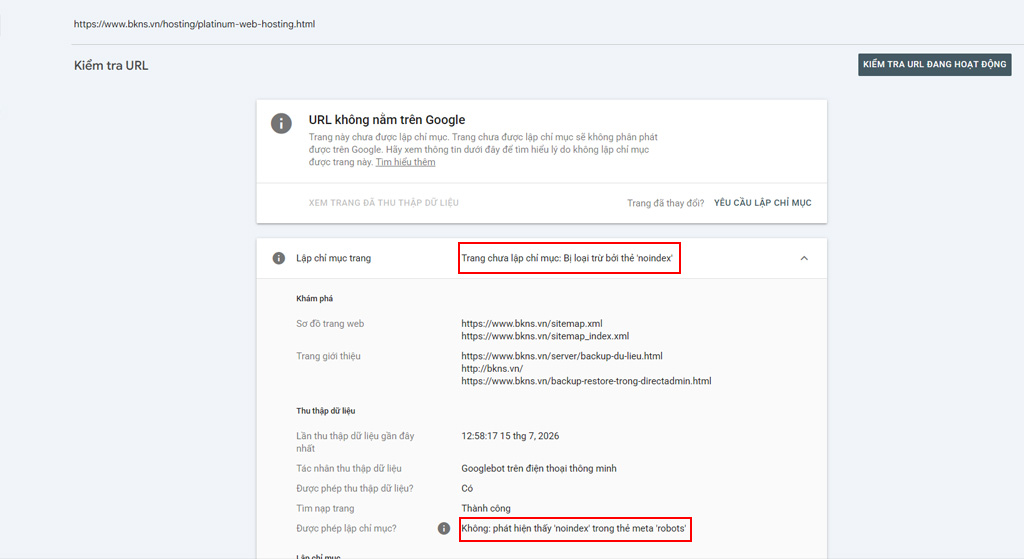
Cách xử lý triệt để tình trạng này cần thực hiện theo thứ tự sau:
Xóa lệnh Disallow của URL đó trong file robots.txt để mở đường cho Googlebot đi vào.
Gắn thẻ meta robots noindex trực tiếp vào mã nguồn HTML của URL đó.
Quay lại Search Console và bấm Xác thực bản sửa lỗi (Validate Fix). Lúc này, bot sẽ đi vào, đọc được lệnh noindex và chính thức xóa trang này khỏi cơ sở dữ liệu.
Hỏi đáp về robots.txt
Quá trình vận hành website thực tế luôn phát sinh những tình huống nằm ngoài lý thuyết. Dưới đây là những thắc mắc chúng tôi thường xuyên nhận được nhất trong quá trình tư vấn cấu trúc kỹ thuật cho doanh nghiệp.
Kích thước tối đa của file robots.txt là bao nhiêu?
Googlebot hiện đang giới hạn dung lượng xử lý của tệp này ở mức 500 kilobytes (KB).
Nếu tệp văn bản của bạn vượt quá giới hạn này, Google sẽ tự động cắt bỏ phần dữ liệu thừa ở phía dưới. Để giữ dung lượng ở mức an toàn, bạn nên sử dụng ký tự đại diện (wildcard) * để nhóm các lệnh cấm theo thư mục gốc, thay vì liệt kê thủ công hàng ngàn URL cụ thể.
Làm sao để ẩn URL đã bị index bằng robots.txt?
Bạn không thể dùng robots.txt để xóa một trang đã nằm trong chỉ mục của Google. Lệnh Disallow chỉ giống như một rào chắn không cho bot đi vào lấy dữ liệu mới, chứ không có quyền ra lệnh xóa dữ liệu cũ.
Để loại bỏ hoàn toàn một URL ra khỏi kết quả tìm kiếm, bạn phải dùng thẻ meta noindex, hoặc sử dụng công cụ Xóa (Removals) có sẵn trên giao diện Search Console để ẩn URL đó đi trong vòng 6 tháng.
Website không có file robots.txt có ảnh hưởng SEO không?
Câu trả lời ngắn gọn là Không. Nếu máy chủ không tìm thấy tệp tin này, các con bot sẽ mặc định hiểu rằng toàn bộ website đều mở cửa tự do. Chúng sẽ tiến hành quét mọi ngóc ngách mà không gặp bất kỳ trở ngại nào.
Tuy nhiên, nếu bạn đang quản lý một website quy mô vừa và lớn (có từ 1.000 trang trở lên), việc thiếu vắng hệ thống điều hướng này sẽ khiến máy chủ lãng phí tài nguyên để quét các trang hệ thống, bộ lọc tìm kiếm, hoặc các trang không mang lại giá trị chuyển đổi.

Tôi là Lê Hưng, là Founder và CEO của SEO VIỆT, với hơn 14 năm kinh nghiệm trong lĩnh vực SEO. Dưới sự lãnh đạo của tôi, SEO VIỆT đã xây dựng uy tín vững chắc và trở thành đối tác tin cậy của nhiều doanh nghiệp. Tôi còn tích cực chia sẻ kiến thức và tổ chức các sự kiện quan trọng, đóng góp vào sự phát triển của cộng đồng SEO tại Việt Nam.





Bài viết liên quan
Topical Authority là gì? Cách lập Topical Map thống trị SEO
Bạn đã bao giờ đổ hàng chục triệu mua backlink, cặm cụi viết những bài...
Bí quyết tối ưu Landing Page chuẩn seo lên top tăng chuyển đổi
Bạn đã bao giờ tự hỏi vì sao trang Landing Page đẹp lung linh, tỷ...
Hướng dẫn cách nghiên cứu từ khóa SEO cho người mới
Bạn đã bao giờ dồn hết tâm huyết viết một bài blog dài hàng ngàn...
Search Intent là gì? 4 Loại Search Intent & Dấu hiệu nhận biết
Bạn đã bao giờ thức trắng đêm viết một bài chuẩn SEO dài 3000 chữ,...
Kỹ thuật SEO E-commerce tối ưu tốc độ & tỷ lệ chuyển đổi
Chi phí quảng cáo trên các nền tảng trả phí đang tăng phi mã. Việc...
Thẻ Hreflang là gì? Cấu hình & Fix lỗi trùng lặp nội dung
Bạn đang mở rộng website ra thị trường quốc tế? Đó là một cột mốc...
Hướng dẫn cách SEO Web toàn tập – Đưa Website lên top 1 Google
Bạn đã bao giờ đổ hàng chục giờ đồng hồ chau chuốt từng con chữ,...
Nguyên nhân vì sao Website của bạn không hiển thị trên Google
Có phải bạn thấy mình đã làm tất cả mọi thứ rồi, nhưng website của...
Cách lập kế hoạch SEO tổng thể đột phá Traffic [Kèm Mẫu]
Bạn đã bao giờ dồn sức sản xuất hàng chục bài viết, miệt mài tối...