Bạn đã đổ bao tâm huyết cho khâu nghiên cứu từ khóa, cẩn thận lên cấu trúc bài viết và khéo léo chèn các yếu tố tối ưu hóa tỷ lệ chuyển đổi chuẩn chỉnh. Thế nhưng, ngày qua ngày, đường link vẫn bặt vô âm tín trên trang kết quả tìm kiếm (SERP). Cảm giác lãng phí cả thời gian lẫn ngân sách SEO thực sự gây nản lòng. Trong bối cảnh thuật toán cập nhật liên tục, Google ngày càng khắt khe hơn trong việc cấp phát “Ngân sách thu thập dữ liệu” (Crawl Budget).
Một bài viết không được index đồng nghĩa với việc bạn nhận về con số 0 tròn trĩnh: không traffic, không thứ hạng, và dĩ nhiên là không có bất kỳ chuyển đổi nào.
Để giải quyết dứt điểm tình trạng này, chúng tôi sẽ cùng bạn đi qua một quy trình chuẩn y khoa SEO. Bài viết này sẽ cung cấp từng bước: Kiểm tra hiện trạng -> Chẩn đoán nguyên nhân gốc rễ -> Cách khắc phục triệt để -> Tối ưu thời gian index siêu tốc.
Cách kiểm tra bài viết đã được Google Index hay chưa (Nhanh & Chuẩn)
Thao tác đầu tiên tôi luôn nhắc nhở các bạn mới làm SEO là phải xác nhận xem Google đã thực sự “đọc” và lưu trữ bài viết đó hay chưa. Trong thế giới SEO, nếu nội dung chưa được lập chỉ mục (index), bài viết của bạn hoàn toàn “vô hình” trên Internet.
Dưới đây là hai phương pháp giúp bạn chẩn đoán chính xác tình trạng này chỉ trong vài chục giây.
Sử dụng cú pháp tìm kiếm thủ công
Đây là mẹo kiểm tra siêu tốc mà tôi thường dùng khi cần check nhanh một URL bất kỳ mà không cần quyền truy cập vào hệ thống quản trị.
Bước 1: Mở trình duyệt web ở chế độ ẩn danh (phím tắt
Ctrl+Shift+Nđối với Windows hoặcCmd+Shift+Ntrên Mac). Thao tác này giúp loại bỏ hoàn toàn lịch sử tìm kiếm cá nhân, đảm bảo kết quả trả về minh bạch nhất.Bước 2: Trên thanh tìm kiếm của Google, nhập chính xác cú pháp
site:url-bai-viet-cua-ban(ví dụ:site:[domain.com/bai-viet-a](https://domain.com/bai-viet-a)) và nhấn Enter.Bước 3: Đọc kết quả. Nếu Google trả về đúng tiêu đề và đoạn mô tả của bài viết đó, chúc mừng bạn, nội dung đã được hệ thống ghi nhận. Ngược lại, nếu màn hình báo không tìm thấy tài liệu nào, bài viết vẫn chưa được index.
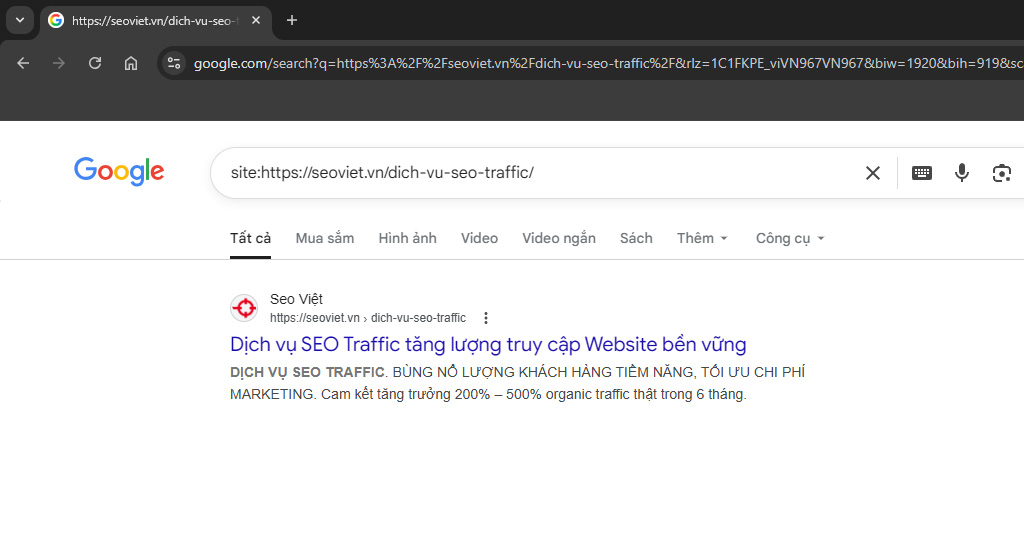
Lưu ý : Rất nhiều bạn mới vào nghề thường đánh đồng giữa việc chưa được index và đã index nhưng văng khỏi top 100.
Nếu bạn search từ khóa SEO mà không thấy bài, nhưng khi dùng lệnh site: bài viết vẫn xuất hiện, nghĩa là Googlebot đã lập chỉ mục thành công. Vấn đề của bạn lúc này là nội dung chưa đủ sức cạnh tranh hoặc sai Search Intent, đòi hỏi phải tối ưu lại On-page, chứ không phải đi ép index lại từ đầu.
Tra cứu trực tiếp trên Google Search Console (Khuyên dùng)
Mặc dù lệnh site: rất nhanh, nhưng đôi khi vẫn có độ trễ nhất định. Để có câu trả lời xác đáng 100% từ chính cơ sở dữ liệu của Google, tôi luôn khuyên bạn nên sử dụng công cụ Google Search Console (GSC).
Bước 1: Truy cập vào giao diện quản trị GSC của website.
Bước 2: Copy đường link bài viết bạn muốn kiểm tra, dán trực tiếp vào thanh Kiểm tra URL (URL Inspection) nằm ở chính giữa góc trên cùng màn hình và nhấn Enter.
Bước 3: Chờ khoảng 1-2 phút để hệ thống trích xuất dữ liệu trực tiếp từ kho lưu trữ (Index).
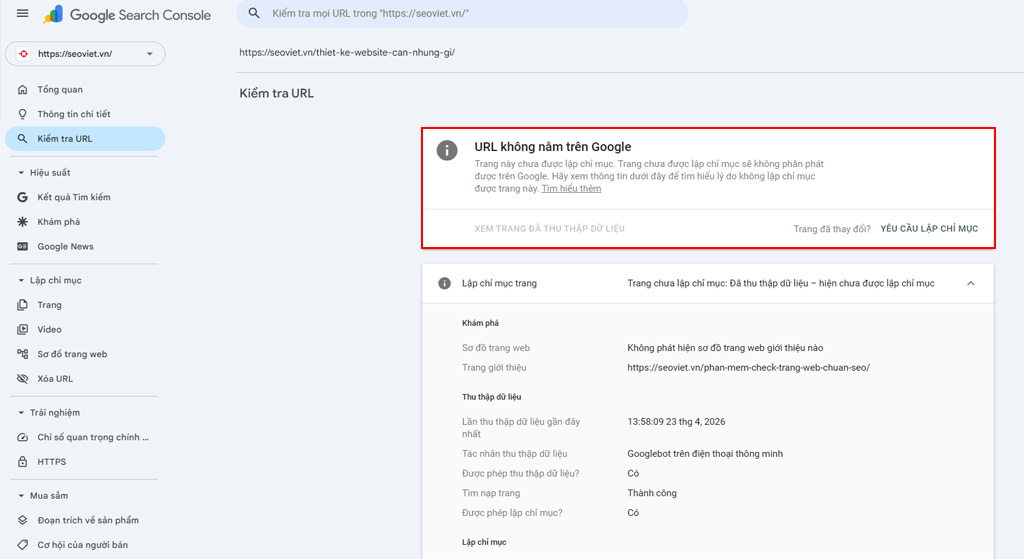
Nếu kết quả trả về là một biểu tượng cảnh báo màu xám kèm dòng chữ “URL không nằm trên Google” (URL is not on Google), điều này xác nhận bài viết của bạn chưa hề tồn tại trong cơ sở dữ liệu tìm kiếm.
Ngay lúc này, đừng vội tắt tab. Hãy chủ động điều hướng bọ trườn bằng cách click ngay vào nút Yêu cầu lập chỉ mục (Request Indexing) nằm ở góc phải. Hành động nhỏ này giống như một lời “nhắc nhở” VIP, giúp URL của bạn được đưa vào hàng đợi ưu tiên để Googlebot nhanh chóng ghé thăm và quét dữ liệu trong lần cào (crawl) tiếp theo.
6 Nguyên nhân kỹ thuật khiến URL bị từ chối lập chỉ mục
Khi nhận được thông báo “URL không nằm trên Google”, cảm giác hụt hẫng là điều khó tránh khỏi. Tuy nhiên, thay vì hoang mang đi submit lại liên tục, tôi luôn khuyên bạn nên dừng lại một nhịp để bắt đúng “bệnh”.
Dưới đây là 6 rào cản kỹ thuật phổ biến nhất khiến hệ thống từ chối lưu trữ bài viết của bạn, kèm theo cách bắt bệnh chuẩn xác nhất.
1. Lỗi chặn Bot từ hệ thống (Robots.txt & Noindex)
Rất nhiều lần tôi phát hiện ra bài viết không thể lên top chỉ vì một sai lầm cực kỳ ngớ ngẩn: Website đang tự đóng cửa từ chối Googlebot. Quá trình thiết kế web hoặc cài đặt plugin vô tình để lại lệnh chặn trong file robots.txt, hoặc gắn nhầm thẻ <meta name="robots" content="noindex"> vào header.
Tại sao: Googlebot là một cỗ máy tuân thủ luật lệ. Khi thấy biển báo “Noindex” hoặc bị chặn từ robots.txt, nó sẽ lập tức quay xe dù bài viết của bạn có xuất sắc đến đâu.
Cách kiểm tra: Mở bài viết, nhấn Ctrl + U (View Source) và bấm Ctrl + F để tìm từ khóa “noindex”. Nhanh hơn nữa, bạn hãy cài đặt các tiện ích mở rộng như SEOquake hoặc Detailed SEO Extension để soi trạng thái Indexability chỉ bằng một cú click.

2. Vướng mắc tại trạng thái Discovered / Crawled (Phổ biến nhất)
Đây là vùng trũng kỹ thuật mà dân làm SEO đau đầu nhất khi đọc báo cáo GSC. Cả hai trạng thái này đều cho thấy Google đã biết đến URL, nhưng lại “ngâm” ở đó không chịu hiển thị ra kết quả tìm kiếm.
Đã phát hiện – hiện chưa được lập chỉ mục (Discovered): Bọ trườn đã thấy link nhưng quyết định lùi lại. Nguyên nhân cốt lõi thường nằm ở sức mạnh hệ thống máy chủ. Nếu VPS/Hosting của bạn phản hồi quá chậm, bot sẽ chủ động hoãn cào dữ liệu để tránh làm sập website. Bạn bắt buộc phải nâng cấp tài nguyên máy chủ hoặc tối ưu lại hệ thống Cache.
Đã thu thập dữ liệu – hiện chưa được lập chỉ mục (Crawled): Bot đã thực sự vào bài, đọc hết chữ nhưng đánh giá nội dung này chưa đủ “ngon” để đưa vào kho dữ liệu. Vấn đề lúc này nằm 100% ở chất lượng bài viết.
3. Lỗi trùng lặp & Xung đột Canonical
Google cực kỳ ghét việc lưu trữ nhiều bài viết có nội dung na ná nhau. Khi hệ thống quét qua và nhận thấy bài viết của bạn quá giống với một URL khác đã tồn tại, nó sẽ tự động gom nhóm chúng lại.
Tại sao: Google sẽ tự động chọn URL cũ hơn hoặc uy tín hơn làm trang chuẩn (Canonical) và tước quyền hiển thị của bài viết mới.
Cách kiểm tra: Dán link vào công cụ Kiểm tra URL của GSC. Cuộn xuống phần Lập chỉ mục, hãy đối chiếu hai dòng: “URL chuẩn do người dùng khai báo” và “URL chuẩn do Google chọn”. Nếu hai đường link này khác nhau, bạn đang dính lỗi trùng lặp.
4. Chất lượng nội dung không đạt chuẩn
Thuật toán hiện tại không chỉ đếm số chữ mà phân tích sâu thấu hiểu ngữ nghĩa. Một bài viết bị dán nhãn Thin content (Nội dung mỏng) chắc chắn sẽ bị loại từ vòng gửi xe.
Tại sao: Nội dung mỏng không có nghĩa là bài viết ngắn, mà là bài viết hời hợt, không giải quyết triệt để Search Intent của người dùng.
Đặc biệt lưu ý: Việc lạm dụng các công cụ AI để sản xuất bài viết hàng loạt mà thiếu đi bước biên tập, kiểm duyệt từ con người là con dao hai lưỡi. Văn bản AI sinh ra thường chung chung, thiếu hụt yếu tố E-E-A-T (Kinh nghiệm thực tế, Chuyên môn). Để khắc phục, bạn phải bổ sung thêm insight cá nhân và các ví dụ thực tiễn.
5. Cấu trúc site rời rạc
Hãy tưởng tượng bài viết của bạn là một hòn đảo hoang giữa đại dương. Không có bất kỳ liên kết nội bộ (Internal Link) nào từ các bài viết khác trỏ về nó. Chúng tôi gọi đây là hiện tượng Orphan Pages (Trang mồ côi).
Tại sao: Googlebot di chuyển từ trang này sang trang khác thông qua các đường link. Không có link trỏ đến đồng nghĩa với việc không có đường dẫn để dòng chảy sức mạnh (Link juice) truyền vào. Bọ trườn sẽ mất rất nhiều thời gian mới mò ra được hòn đảo hoang này.
Cách kiểm tra: Quét toàn bộ website bằng các công cụ Site Audit (như Ahrefs hoặc Screaming Frog) để lọc ra danh sách Orphan Pages. Sau đó, hãy chủ động chèn link từ các bài viết cũ có nhiều traffic sang bài mới.
6. Vấn đề về hiệu suất máy chủ (Lỗi 5xx) và Crawl Budget
Nếu website của bạn sở hữu một cấu trúc đồ sộ với hàng ngàn bài viết, bạn phải làm quen với khái niệm Ngân sách thu thập dữ liệu (Crawl Budget).
Tại sao: Google chỉ cấp cho mỗi website một khoảng thời gian hữu hạn để cào dữ liệu mỗi ngày. Nếu máy chủ của bạn thường xuyên trả về Lỗi 5xx (Server Error) hoặc tốc độ tải trang ì ạch, bọ trườn sẽ tiêu sạch ngân sách trước khi kịp đến lượt các bài viết mới.
Cách kiểm tra: Theo dõi sát sao phần “Số liệu thống kê về quá trình thu thập dữ liệu” trong GSC. Hãy đảm bảo tỷ lệ lỗi máy chủ luôn ở mức 0% và thời gian phản hồi trung bình của server nằm ở ngưỡng an toàn. Dọn dẹp các link hỏng (404) cũng là cách tuyệt vời để tiết kiệm Crawl Budget.
Quy trình 5 bước “Ép” Google Index bài viết siêu tốc
Sau khi đã rà soát và triệt tiêu 6 rào cản kỹ thuật vừa nêu, đã đến lúc bạn chuyển từ thế bị động sang chủ động. Đừng xuất bản bài viết rồi ngồi chờ mỏi mòn để bọ trườn tự mò tới.
Dưới đây là quy trình thực chiến tôi luôn áp dụng để “ép” hệ thống phải chú ý, quét và ghi nhận URL mới chỉ trong thời gian cực ngắn.
Bước 1: Fix lỗi kỹ thuật On-page & Bổ sung Internal Link
Đừng vội khai báo link ngay nếu nội dung chưa thực sự hoàn thiện. Hãy rà soát lại bố cục bài viết, bổ sung thêm hình ảnh thực tế, số liệu chứng minh hoặc những góc nhìn độc bản để gia tăng độ sâu (Depth Content).
Khi bài đã đủ “chất”, bạn cần tạo ra một con đường đủ rộng để đón bot. Hãy mở các công cụ đo lường như Ahrefs hoặc báo cáo GSC, lọc ngay danh sách những bài viết cũ đang có lượng truy cập cao nhất mỗi ngày.
Từ những bài top traffic đó, hãy khéo léo chèn Internal Link trỏ thẳng về URL bạn vừa xuất bản. Kỹ thuật này giúp truyền tải sức mạnh (Link juice) cực kỳ hiệu quả, điều hướng Googlebot đi thẳng từ trang cũ sang trang mới một cách mượt mà nhất.
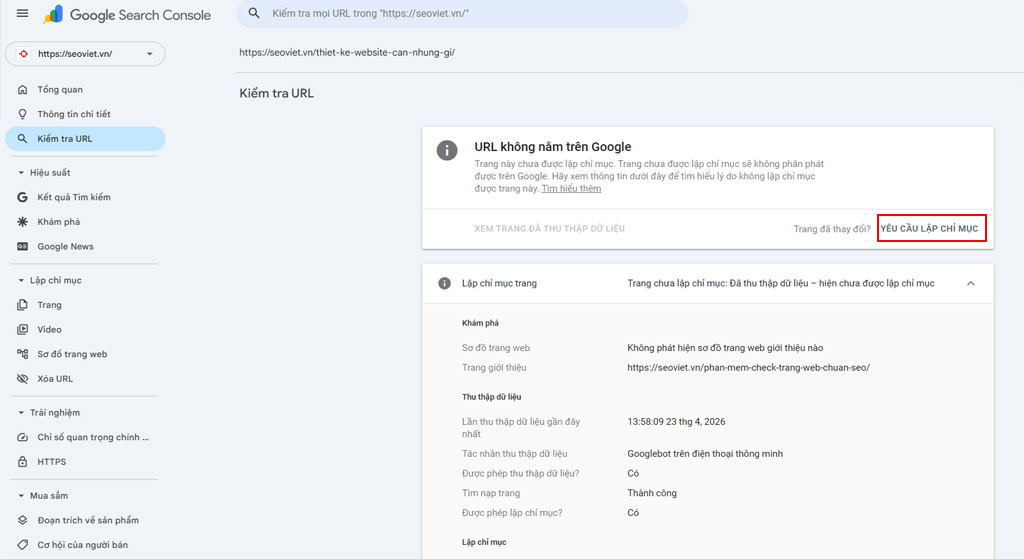
Bước 2: Request Indexing thủ công trên GSC
Khi đã tự tin bài viết không còn lỗi On-page và hệ thống liên kết nội bộ đã vững chắc, thao tác tiếp theo là “gõ cửa” trực tiếp kho dữ liệu của Google.
Mở bảng điều khiển Google Search Console.
Dán URL cần ép index vào thanh tìm kiếm trên cùng.
Click ngay vào nút Yêu cầu lập chỉ mục (Request Indexing).
Thao tác này đưa URL của bạn vào danh sách chờ ưu tiên. Tuy nhiên, hãy nhớ chỉ bấm một lần duy nhất. Việc spam nút yêu cầu liên tục không giúp quá trình diễn ra nhanh hơn, thậm chí còn khiến hệ thống đánh dấu hành vi bất thường.
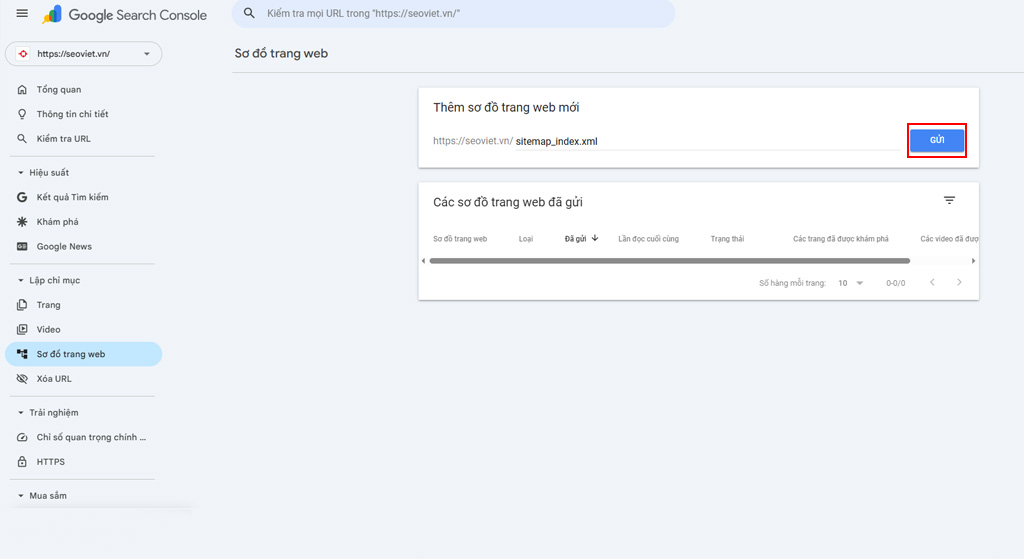
Bước 3: Cấu hình và khai báo lại Sitemap.xml
Sitemap đóng vai trò như một tấm bản đồ chi tiết, dẫn đường cho bọ trườn len lỏi vào từng ngóc ngách trên website. Bất kỳ URL mới nào được xuất bản cũng phải ngay lập tức có mặt trên tấm bản đồ này.
Hãy kiểm tra lại plugin SEO (như Yoast hoặc Rank Math nếu bạn dùng WordPress) để đảm bảo sitemap tự động cập nhật đường link mới.
Tiếp đó, copy đường dẫn sitemap (thường là [domain.com/sitemap_index.xml](https://domain.com/sitemap_index.xml)), vào lại mục Sơ đồ trang web trên GSC và nhấn gửi. Bước này giúp “Ping” trực tiếp tín hiệu cập nhật cấu trúc site cho máy chủ tìm kiếm.
Bước 4: Khai thác sức mạnh của Indexing API (Nâng cao)
Nếu bạn quản trị những hệ thống lớn, cần tốc độ index tính bằng giây, thao tác thủ công là không đủ. Đó là lúc chúng ta phải dùng đến Google Indexing API.
Phương pháp này cho phép website giao tiếp trực tiếp qua API với máy chủ Google mỗi khi có bài viết mới được thêm, sửa hoặc xóa.
Với hệ thống mã nguồn mở: Bạn có thể dễ dàng cài đặt các plugin tích hợp sẵn API chỉ với vài cú click thiết lập cấu hình JSON.
Hiệu quả thực tế: Kỹ thuật này là “vũ khí tối thượng” cho các trang tin tức cập nhật từng giờ hoặc các sàn thương mại điện tử cần index nhanh hàng ngàn sản phẩm.
Bước 5: Kéo mồi Traffic (Social Signals & Paid Ads)
Googlebot đánh giá cực cao những URL nhận được tương tác từ người dùng thật ngay từ những phút đầu xuất bản. Lượng truy cập ban đầu này chính là “mồi lửa” kích hoạt quá trình lập chỉ mục siêu tốc.
Hãy chia sẻ ngay đường link bài viết lên các nền tảng mạng xã hội như Facebook, LinkedIn hay X. Tín hiệu mạng xã hội (Social Signals) báo hiệu cho công cụ tìm kiếm rằng đây là một nội dung đang được cộng đồng quan tâm.
Mạnh tay hơn, tôi thường trích một phần nhỏ ngân sách để chạy quảng cáo mồi. Việc thiết lập một chiến dịch Google Ads tìm kiếm hoặc chạy các widget quảng cáo tự nhiên qua MGID sẽ đẩy hàng trăm lượt click từ người dùng thật vào bài ngay lập tức. Dòng traffic chất lượng này không chỉ giúp ép index cực mạnh mà còn tạo đà để URL nhanh chóng vươn lên các vị trí cao trên trang nhất.
Theo dõi sức khỏe Website toàn diện để phòng tránh (FAQ)
Khi đã nắm vững quy trình xử lý lỗi kỹ thuật ở phần trước, bạn hoàn toàn có thể tự tin đưa bất kỳ bài viết nào lên kết quả tìm kiếm. Tuy nhiên, một người làm SEO chuyên nghiệp sẽ không ngồi chờ website “kêu cứu” rồi mới loay hoay đi chữa cháy. Chúng tôi luôn định hướng bạn chuyển dịch sang tư duy “phòng bệnh hơn chữa bệnh”. Việc chủ động rà soát kỹ thuật định kỳ chính là chìa khóa để bảo vệ dòng chảy traffic.
Dưới đây là những giải đáp cặn kẽ giúp bạn làm chủ hoàn toàn hệ thống của mình.
Mất bao lâu để Google index một bài viết mới một cách tự nhiên?
Thời gian bọ trườn phát hiện và lập chỉ mục không tuân theo một mốc thời gian cố định. Tốc độ này được quyết định bởi hai biến số cốt lõi: Ngân sách thu thập dữ liệu (Crawl Budget) và Độ uy tín của Domain (Trust).
Đối với website mới hoặc ít cập nhật: Bọ trườn sẽ phân bổ rất ít tài nguyên để ghé thăm. Bạn có thể phải kiên nhẫn chờ đợi từ vài ngày, thậm chí đến vài tuần để bài viết xuất hiện trên kết quả tìm kiếm.
Đối với website có cấu trúc chuẩn, tín hiệu traffic tốt: Nếu bạn duy trì được tần suất xuất bản đều đặn, Googlebot sẽ “nằm vùng” thường xuyên hơn. Trong trường hợp này, thời gian index có thể cực kỳ nhanh, chỉ tính bằng phút hoặc vài giờ.
Có nên lạm dụng các Tool/Dịch vụ ép index của bên thứ 3 không?
Câu trả lời của tôi luôn là không. Đa số các dịch vụ bên thứ ba hiện nay hứa hẹn tốc độ index siêu tốc nhưng thực chất lại vận hành dựa trên cơ chế bắn backlink rác (spam links) hoặc tạo các chuyển hướng chéo.
Đây là một canh bạc chứa đựng rủi ro khổng lồ. Việc ép Googlebot đi vào URL bằng mọi giá có thể giúp bài viết hiển thị nhanh chóng, nhưng sau đó hệ thống sẽ ngay lập tức De-index (mất chỉ mục). Hậu quả tồi tệ nhất là website của bạn bị phạt thuật toán (Penalty), kéo tụt toàn bộ thứ hạng từ khóa.
Thay vì tìm kiếm đường tắt, hãy bám sát chiến lược Whitehat (Mũ trắng). Việc tập trung khai thác công cụ Google Indexing API chính thống, kết hợp với cấu trúc Internal Link chặt chẽ luôn là phương án an toàn và hiệu quả nhất.
Xây dựng quy trình cảnh báo sớm lỗi Index như thế nào?
Đừng để đến lúc bài viết hoàn toàn biến mất mới bắt đầu đi tìm nguyên nhân. Bạn hoàn toàn có thể đón đầu các rủi ro bằng cách theo dõi sát sao dữ liệu từ Google Search Console (GSC) kết hợp với các đợt quét tự động.
Đầu tiên, hãy thiết lập thói quen kiểm tra báo cáo Trang (Pages) -> Trạng thái lập chỉ mục (Indexing status) trên GSC hàng tuần. Hãy nhạy bén với những đợt tăng vọt bất thường của các dải lỗi phổ biến như Discovered hoặc Crawled – currently not indexed.
Tiếp theo, hãy thiết lập lịch quét tự động định kỳ bằng tính năng Site Audit của Ahrefs hoặc Screaming Frog. Việc nhận các báo cáo hàng tuần về liên kết gãy (Lỗi 404), vòng lặp chuyển hướng hay các trang bị cô lập (Orphan pages) sẽ giúp bạn dọn dẹp sạch sẽ các điểm nghẽn kỹ thuật trước khi chúng lan rộng.
Bài viết đã được Index nhưng đột nhiên biến mất khỏi Google (De-indexed)?
Hiện tượng “văng index” này rất phổ biến và thường khiến nhiều bạn hoang mang. Nguyên nhân hàng đầu là do thuật toán vừa quét lại và dán nhãn bài viết của bạn là Thin Content (nội dung mỏng, copy hoặc không giải quyết được Search Intent).
Một lý do khác có thể đến từ máy chủ. Nếu server trả về lỗi 500/503 đúng vào khoảnh khắc bot đang cào dữ liệu, nó sẽ tạm thời loại URL đó ra khỏi cơ sở dữ liệu. Ngoài ra, việc bạn tối ưu lại bài, thay đổi URL nhưng lại quên cấu hình chuyển hướng 301 cũng là một nguyên nhân trực tiếp.
Cách xử lý triệt để nhất là rà soát lại toàn bộ yếu tố On-page. Hãy bổ sung ngay các giá trị độc bản, số liệu thực tế để tạo ra nội dung tươi mới (Fresh content). Sau khi bài viết đã đủ sức nặng, hãy quay lại GSC và yêu cầu lập chỉ mục lại.
Làm sao để tối ưu hóa “Crawl Budget” cho các website có hàng chục ngàn bài viết?
Với những dự án lớn chứa hàng ngàn bài viết đa chủ đề hay hàng loạt các trang thủ thuật, Ngân sách thu thập dữ liệu (Crawl Budget) là yếu tố sống còn. Nếu không kiểm soát tốt, bọ trườn sẽ tiêu sạch ngân sách trước khi kịp đọc các bài viết chủ lực.
Bước tối ưu đầu tiên là chia nhỏ file Sitemap.xml. Khi số lượng URL vượt quá giới hạn hoặc quá đồ sộ, hãy phân tách chúng theo từng danh mục cụ thể và ưu tiên đưa những cụm nội dung quan trọng nhất lên vị trí đầu.
Cuối cùng, bạn phải tận dụng triệt để sức mạnh của file robots.txt. Hãy thiết lập các câu lệnh chặn bot quét những khu vực không mang lại giá trị SEO như: trang giỏ hàng, hệ thống bộ lọc tìm kiếm (faceted navigation), hay các trang tag vô nghĩa. Càng loại bỏ được nhiều URL rác, hệ thống của bạn càng tối ưu được chi phí cào dữ liệu.

Tôi là Lê Hưng, là Founder và CEO của SEO VIỆT, với hơn 14 năm kinh nghiệm trong lĩnh vực SEO. Dưới sự lãnh đạo của tôi, SEO VIỆT đã xây dựng uy tín vững chắc và trở thành đối tác tin cậy của nhiều doanh nghiệp. Tôi còn tích cực chia sẻ kiến thức và tổ chức các sự kiện quan trọng, đóng góp vào sự phát triển của cộng đồng SEO tại Việt Nam.





Bài viết liên quan
Topical Authority là gì? Cách lập Topical Map thống trị SEO
Bạn đã bao giờ đổ hàng chục triệu mua backlink, cặm cụi viết những bài...
Bí quyết tối ưu Landing Page chuẩn seo lên top tăng chuyển đổi
Bạn đã bao giờ tự hỏi vì sao trang Landing Page đẹp lung linh, tỷ...
Hướng dẫn cách nghiên cứu từ khóa SEO cho người mới
Bạn đã bao giờ dồn hết tâm huyết viết một bài blog dài hàng ngàn...
Search Intent là gì? 4 Loại Search Intent & Dấu hiệu nhận biết
Bạn đã bao giờ thức trắng đêm viết một bài chuẩn SEO dài 3000 chữ,...
Kỹ thuật SEO E-commerce tối ưu tốc độ & tỷ lệ chuyển đổi
Chi phí quảng cáo trên các nền tảng trả phí đang tăng phi mã. Việc...
Thẻ Hreflang là gì? Cấu hình & Fix lỗi trùng lặp nội dung
Bạn đang mở rộng website ra thị trường quốc tế? Đó là một cột mốc...
Hướng dẫn cách SEO Web toàn tập – Đưa Website lên top 1 Google
Bạn đã bao giờ đổ hàng chục giờ đồng hồ chau chuốt từng con chữ,...
Nguyên nhân vì sao Website của bạn không hiển thị trên Google
Có phải bạn thấy mình đã làm tất cả mọi thứ rồi, nhưng website của...
Cách lập kế hoạch SEO tổng thể đột phá Traffic [Kèm Mẫu]
Bạn đã bao giờ dồn sức sản xuất hàng chục bài viết, miệt mài tối...